Contents
Share on:



The Challenge of Flexibility in Object Detection

In computer vision, object detection models have traditionally operated within a predefined set of classes. But what if we could break free from this constraint, enabling models to detect new objects without the need for retraining? Enter Grounding DINO, a groundbreaking zero-shot object detection model developed by Ultralytics and Roboflow.

The Challenge of Flexibility in Object Detection
Traditional object detection models face a significant limitation: their inability to adapt to new objects without extensive retraining. Each time the set of recognizable objects needs to be expanded or modified, the arduous process of collecting data, labeling it, and retraining the model ensues. This approach is not only time-consuming but also expensive.
Zero-Shot Detection: A Paradigm Shift
Grounding DINO aims to disrupt this status quo by introducing the concept of zero-shot detection. Unlike traditional models, which require retraining to recognize new objects, Grounding DINO can detect objects simply by changing the prompt given to the model. By leveraging advanced machine learning techniques, the model can identify objects based on textual descriptions without the need for additional training data.
Performance and Versatility
Grounding DINO boasts impressive performance metrics, achieving a 52.5 AP on the COCO detection zero-shot transfer benchmark without any training data from COCO. With fine-tuning using COCO data, it reaches a remarkable 63.0 AP. Moreover, it sets a new record on the ODinW zero-shot benchmark with a mean of 26.1 AP.
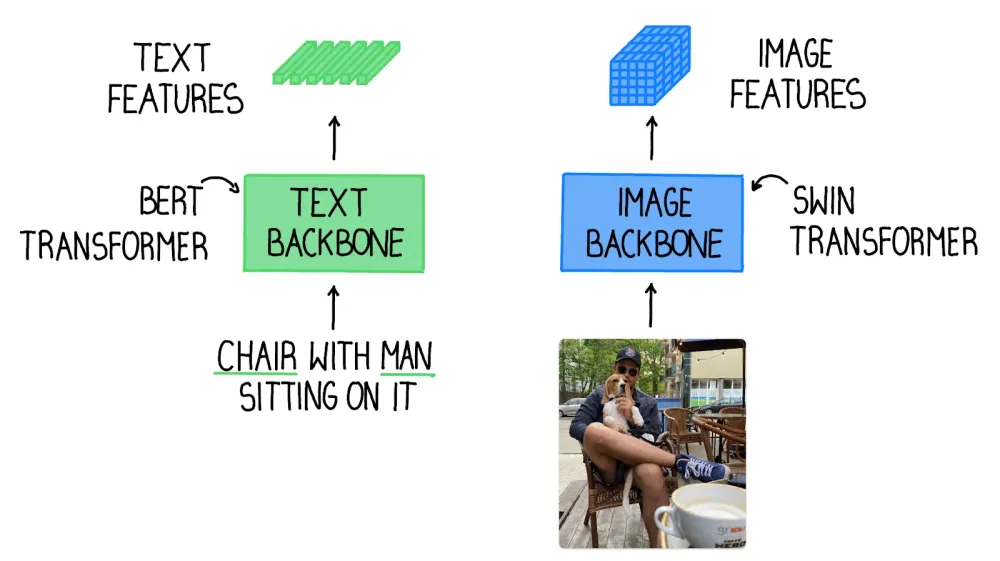
How Grounding DINO Works
At its core, Grounding DINO merges concepts from two influential papers: DINO and GLIP. DINO introduces a transformer-based detection method that optimizes object detection performance and eliminates the need for handcrafted modules like Non-Maximum Suppression (NMS). GLIP focuses on phrase grounding, linking textual descriptions to visual representations in images or videos.
Grounding DINO's architecture comprises text and image backbones, a feature enhancer for cross-modality feature fusion, language-guided query selection, and a cross-modality decoder. This intricate design allows the model to effectively combine textual descriptions with visual features for accurate object detection.
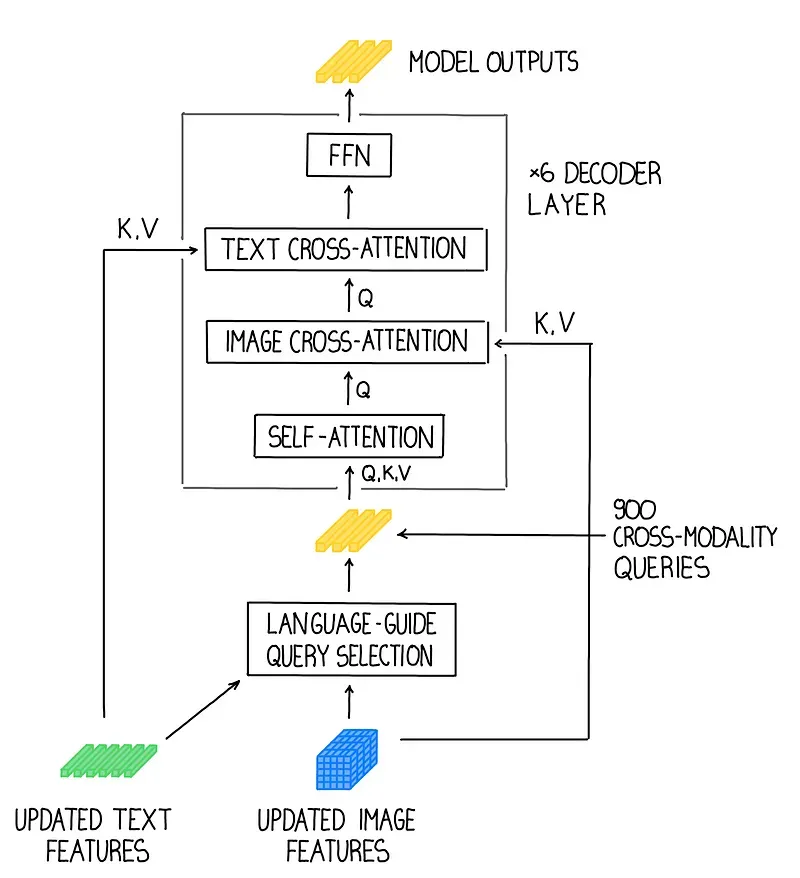
Real-World Applications
The versatility of Grounding DINO opens a myriad of applications across various industries. From autonomous vehicles to medical imaging and surveillance systems, the model's ability to adapt to novel objects and scenarios makes it invaluable for tackling real-world challenges.
Addressing Challenges with Annotated Data: A Real-World Example
Upon joining Eizen, a leading AI company, we encountered a common challenge faced by many in the field: the need to annotate large volumes of data for new use cases. As our projects expanded into uncharted territories, we found ourselves grappling with the time-consuming and labor-intensive task of data annotation.
However, our journey took a transformative turn with the introduction of Grounding DINO. This innovative zero-shot object detection model proved to be a game-changer, offering a solution to our data annotation woes. By leveraging Grounding DINO's unique capabilities, we were able to annotate data swiftly and accurately, even for objects outside the predefined set of classes.
With Grounding DINO, the process of data annotation became streamlined and efficient, allowing us to focus our resources on exploring new use cases and pushing the boundaries of AI innovation. Our experience with Grounding DINO exemplifies its versatility and applicability in real-world scenarios, reaffirming its status as a groundbreaking tool in the field of computer vision.
Accelerating Object Detection for Video Analytics: A Practical Application
At our platform, we specialize in providing analytics for videos and cameras, a domain where precision and efficiency are paramount. As we embarked on building detection models to enhance our platform's capabilities, we encountered a critical bottleneck: the time and effort required for data annotation.
Given the diverse nature of our platform, which demands different detection models for various use cases, traditional annotation methods simply couldn't keep pace with our needs. However, our quest for a solution led us to Grounding DINO.
Grounding DINO emerged as the perfect tool to address our annotation challenges. Its ability to perform zero-shot object detection offered a revolutionary approach to data annotation, significantly reducing the time and resources required to annotate vast amounts of data.
With Grounding DINO at our disposal, we were able to speed up building detection models for our platform's video analytics capabilities. By leveraging its advanced capabilities, we could swiftly annotate data for diverse objects and scenarios, empowering us to deliver cutting-edge solutions to our clients in record time.
The integration of Grounding DINO into our workflow not only streamlined our operations but also unlocked new possibilities for innovation in the realm of video analytics. Its impact on our platform underscores its value as a transformative tool for accelerating object detection tasks in real-world applications.
Conclusion: Paving the Way for Innovation
Grounding DINO represents a paradigm shift in object detection, offering a highly adaptable and flexible approach to zero-shot detection. By transcending the limitations of traditional models, it paves the way for more innovative applications in computer vision and beyond.
In a world where flexibility and adaptability are paramount, Grounding DINO stands as a beacon of innovation, reshaping the landscape of object detection for years to come.