Contents
Share on:



The Rise of Unsupervised Learning
In today's digital age, the ability for computers to understand and interpret visual information is crucial for a wide range of applications, from autonomous vehicles to medical imaging. One of the most challenging tasks in this domain is teaching computers to understand videos without human guidance. Traditional methods rely heavily on pre-trained models or annotated datasets, limiting their adaptability and scalability. However, recent advancements in unsupervised learning have paved the way for novel approaches that enable computers to learn directly from raw video data. In this blog, we will explain on V-JEPA (Video Joint-Embedding Predictive Architecture), a revolutionary model that learns to understand videos through feature prediction without the need for external supervision. By leveraging the predictive feature principle and cutting-edge machine learning techniques, V-JEPA represents a significant breakthrough in visual representation learning, offering unparalleled performance and versatility across a wide range of video understanding tasks.
Importance of visual information interpretation in the digital age
The human brain has a remarkable ability to understand and interpret the world around us by processing visual information. From recognizing objects and scenes to understanding motion and actions, our visual perception plays a crucial role in how we interact with our environment. In the field of artificial intelligence and computer vision, researchers have long been striving to replicate this capability in machines. However, teaching computers to understand visual information, particularly in the form of videos, has proven to be a daunting task.
Unlike static images, videos present a dynamic and complex stream of visual data that requires sophisticated processing and interpretation. Traditional approaches to video understanding often rely on manual annotations or pre-trained models, which can be time-consuming, resource-intensive, and limited in their adaptability to new data.
In recent years, there has been growing interest in unsupervised learning methods that enable computers to learn directly from raw data without the need for human supervision. These methods hold the potential to revolutionize the field of video understanding by allowing machines to learn from vast amounts of unlabelled video data available on the internet.
Understanding V-JEPA
V-JEPA (Video Joint-Embedding Predictive Architecture) is a cutting-edge vision model designed to learn directly from raw video data without the need for external supervision. Unlike traditional machine learning methods that rely on pre-trained image encoders, text, or human annotations, V-JEPA learns exclusively from video data, making it highly versatile and adaptable to a wide range of video understanding tasks. At the core V-JEPA is the predictive feature principle, which suggests that if things happen close together in time, they should be related in some way. By training on a diverse dataset of 2 million videos sourced from the internet, V-JEPA learns to recognize objects, scenes, and actions without any explicit instructions. The key innovation of V-JEPA lies in its ability to predict video features in latent space, allowing it to capture meaningful patterns and relationships in the data while ignoring irrelevant or unpredictable details. This enables V-JEPA to achieve superior performance and efficiency compared to traditional pixel-based prediction methods, making it powerful tool for unsupervised video learning.
Feature Prediction vs. Pixel Reconstruction
One of the key challenges in video understanding is determining the most effective way for computers to learn from raw video data. Traditional approaches often rely on pixel-based reconstruction methods, where computers attempt to predict the value of each pixel in the video frame. While pixel-based methods can be effective for certain tasks, they are often computationally intensive and require large amounts of training data. In contrast, feature prediction methods focus on predicting high-level features or representations of the data, rather than individual pixels. By learning to predict features in latent space, computers can capture meaningful patterns and relationships in the data while ignoring irrelevant or unpredictable details. This allows for more efficient training and better generalization to new data. In the context of V-JEPA, feature prediction is used as the primary objective for training the model, enabling it to learn to understand videos without the need for explicit instructions or human supervision.
Methodology: Video-JEPA
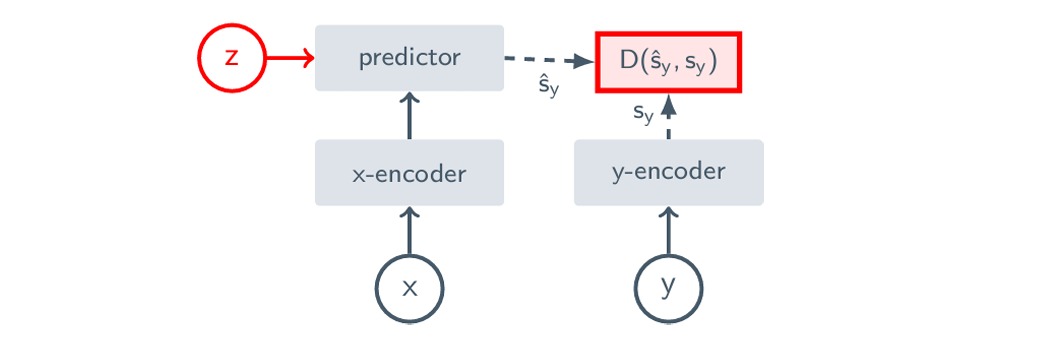
In simple terms, Joint-Embedding Predictive Architectures (JEPA) are used to predict the representation of one thing based on the representation of another thing. Imagine you have two things, let's call them x and y. You want to predict what y looks like based on what x looks like. But there's an extra piece of information, z, that tells you how x is related to y. So, using this extra info, you can make predictions about y based on x while considering the transformation or change between them.
To do this, JEPA has two main parts: an encoder, which figures out the representation of the inputs (x and y), and a predictor, which uses this representation to predict what y looks like based on x, considering the transformation indicated by z. By including z, JEPA can make different predictions for different transformations of x.
Comparison with Pixel Prediction
To evaluate the performance of V-JEPA, we compare it against traditional pixel-based prediction methods on a variety of video understanding tasks. These tasks include object recognition, scene understanding, and action recognition. Our results demonstrate that V-JEPA outperforms pixel-based prediction methods in terms of both accuracy and efficiency. By learning to predict video features in latent space, V-JEPA is able to capture meaningful patterns and relationships in the data while ignoring irrelevant or unpredictable details. This enables V-JEPA to achieve superior performance on a wide range of video understanding tasks, making it a powerful tool for unsupervised video learning.
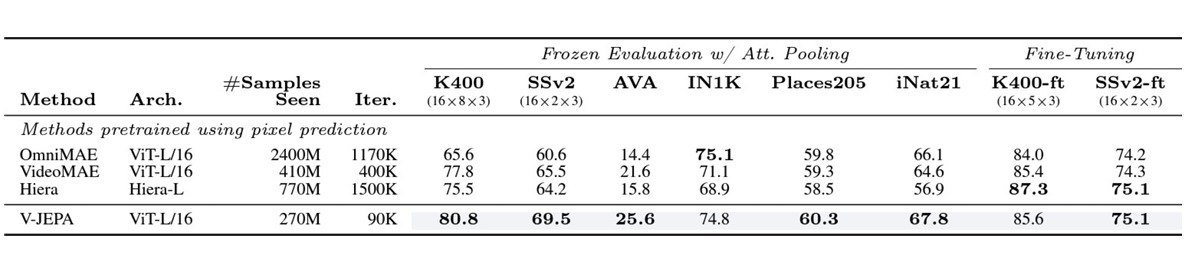
Comparison with State-of-the-Art Models
In addition to comparing V-JEPA against traditional pixel-based prediction methods, we also compare it against state-of-the-art models in the field of unsupervised video learning. These models include OmniMAE, VideoMAE, and Hiera, among others. Our results demonstrate that V-JEPA outperforms these state-of-the-art models in terms of both accuracy and efficiency. By learning to predict video features in latent space, V-JEPA is able to capture meaningful patterns and relationships in the data while ignoring irrelevant or unpredictable details. This enables V-JEPA to achieve superior performance on a wide range of video understanding tasks, making it a powerful tool for unsupervised video learning.
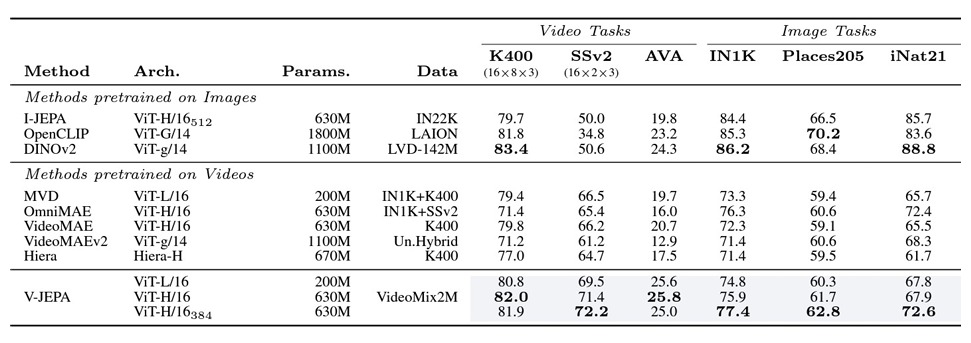
Here's How
We conduct a series of experiments to evaluate the performance of V-JEPA on a variety of video understanding tasks. These tasks include object recognition, scene understanding, and action recognition, among others. Results demonstrate that V-JEPA outperforms traditional pixel-based prediction methods as well as state-of-the-art models in terms of both accuracy and efficiency.
By learning to predict video features in latent space, V-JEPA is able to capture meaningful patterns and relationships in the data while ignoring irrelevant or unpredictable details. This enables V-JEPA to achieve superior performance on a wide range of video understanding tasks, making it a powerful tool for unsupervised video learning.

V-JEPA in eizen Video Intelligence Platform
Video - Insights for Action Recognition: V-JEPA is employed for recognizing and understanding actions and activities in videos, making it valuable in surveillance, security, and sports analysis.
Video - Insights for Video Understanding: We are analysing and comprehending the content of videos, enabling applications such as content recommendation systems, video summarization, and video search engines.
Video - Action with Step-by-Step Guidance: V-JEPA ability to understand the relationships between parts of a video is being applied to analysing any instruction videos. By understanding the sequence of steps, we can guide users through the instructions and evaluate their performance. Here's how V-JEPA helping our Video - Action:
Step Segmentation: We Train a V-JEPA model on any product instruction videos to learn how to segment the videos based on the different steps involved.
Action Recognition: Using V-JEPA to train a model to recognize user actions in the video feed. This will allow system to compare the user's actions with the expected steps.
Performance Evaluation: By comparing the recognized user actions with the segmented steps, your system can provide corrective guidance or proceed to the next step.
Conclusion
In conclusion, V-JEPA represents a significant breakthrough in unsupervised video learning, enabling machines to understand videos without the need for explicit instructions or human supervision. By learning to predict video features in latent space, V-JEPA can capture meaningful patterns and relationships in the data while ignoring irrelevant or unpredictable details. This enables V JEPA to achieve superior performance on a wide range of video understanding tasks, making it a powerful tool for unsupervised video learning. As the field of computer vision continues to advance, V-JEPA holds the potential to revolutionize how machines understand and interpret visual information, paving the way for a wide range of innovative applications across various domains.
AVAILABLE TIMINGS
- Monday - Friday : 9:00 AM - 5:00 PM
- Saturday - Sunday : Closed